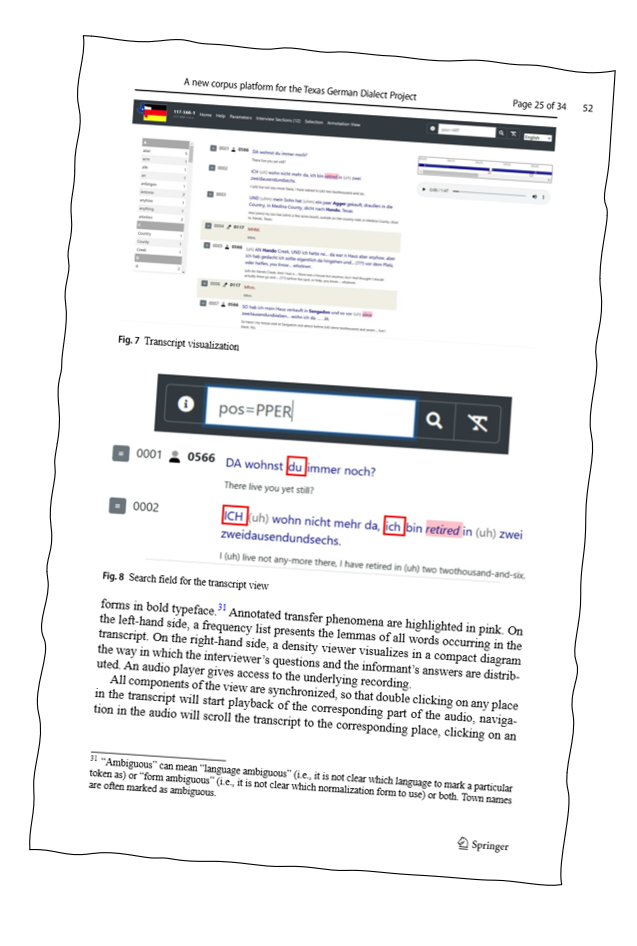
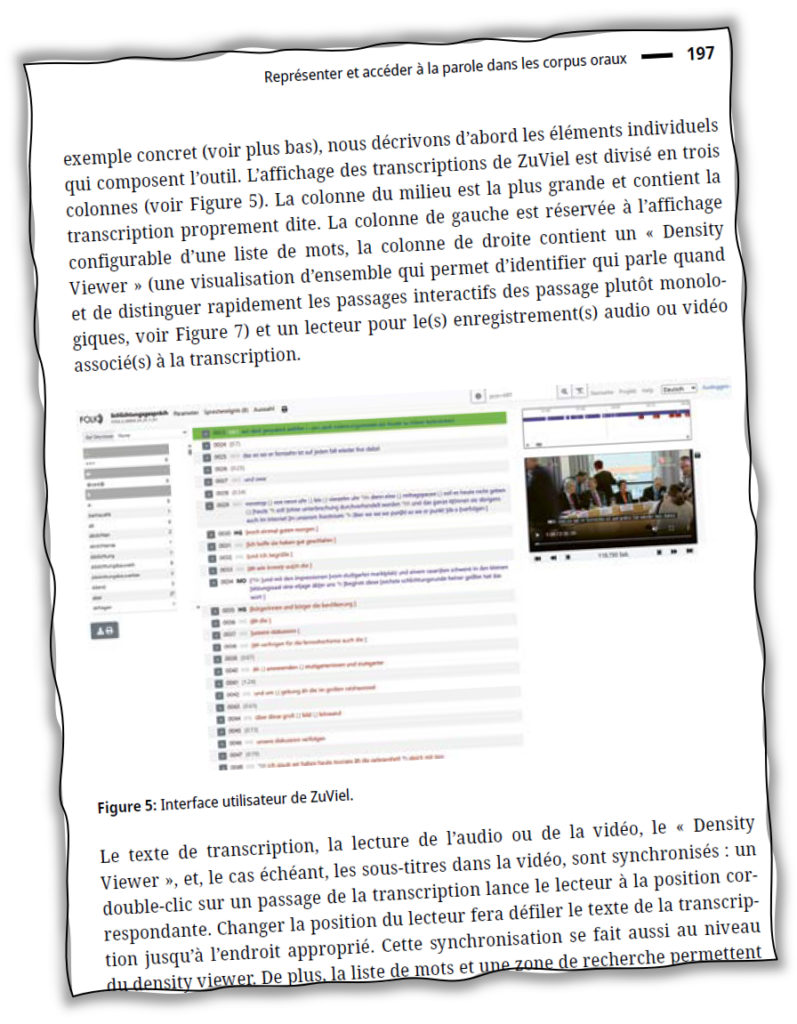
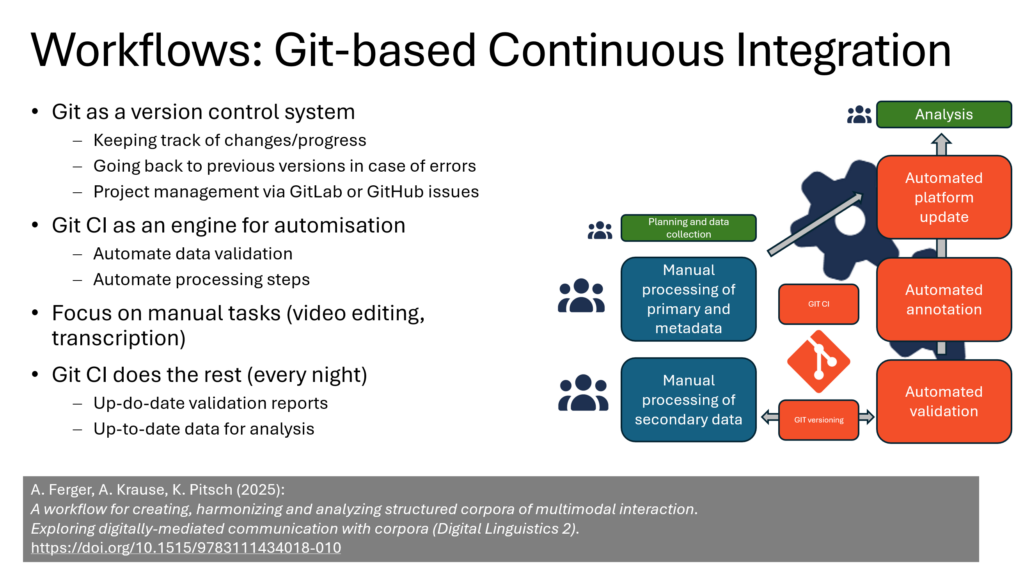
Two more publications on ZuMult are now available in open access:
Schmidt, Thomas; Ferger, Anne & Frick, Elena (2026): Putting things on top of other things: The ZuMult platform for multimodal corpora and its ecosystem. In: Grisot, Christina et al. (Hrsg.): Selected Papers of the CLARIN Annual Conference 2025. https://doi.org/10.3384/ecp222.1601
Schmidt, Thomas; Blevins, Margaret; Boas, Hans & Gilbert, Glenn (2026): The Texas German Dialect Project Corpus as a Diachronic Resource for Investigating Language Contact. In: Proceedings of the First Workshop on Dialects in NLP — A Resource Perspective. ELRA, 221–229. https://doi.org/10.63317/3s622jzdgwuj
ZuMult was also presented at the following occasions:
The International Conference on Conversation Analysis (ICCA) in Edmonton, Canada:
Schmidt, Thomas & Pitsch, Karola: Search, Zoom in, Freeze, Zoom out, Switch, Freeze, … – Supporting video analysis in a corpus platform. Panel „Data in CA: Preparing, sharing, and reusing recordings from naturally occurring interaction continuation“, Sunday, June 28, 2026.
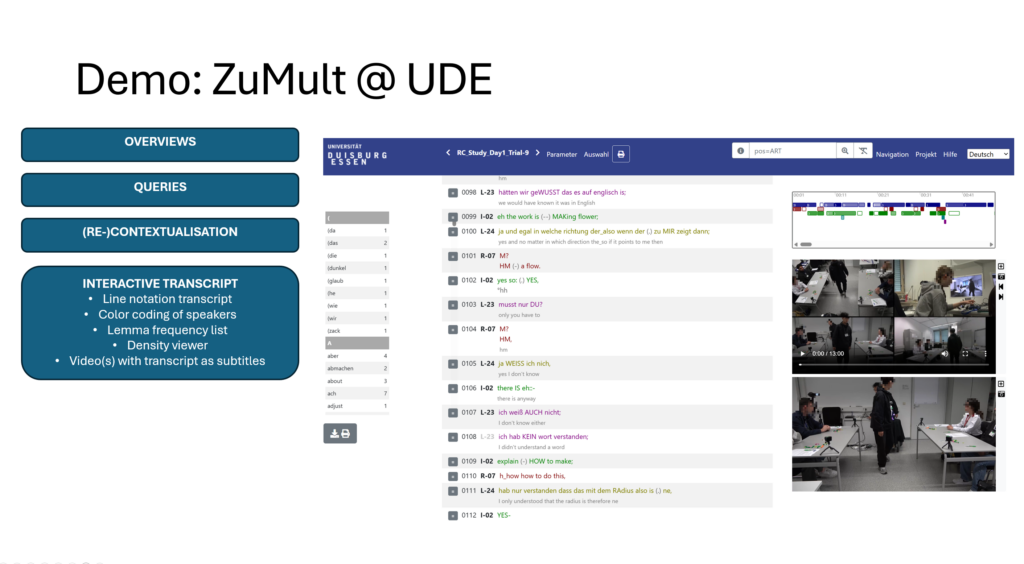
Netzwerktag „Digitalität in den Geisteswissenschaften“, Universität Duisburg-Essen:
Pitsch, Karola; Bergmann, Felix; Ferger, Anne & Schmidt, Thomas: Korpora und Forschungsdatenmanagement in der AG Multimodale Kommunikation, Soziale Interaktion & Technologie. Hochschulöffentlicher Netzwerktag „Digitalität in den Geisteswissenschaften“, Universität Duisburg-Essen, 30. Juni 2026.