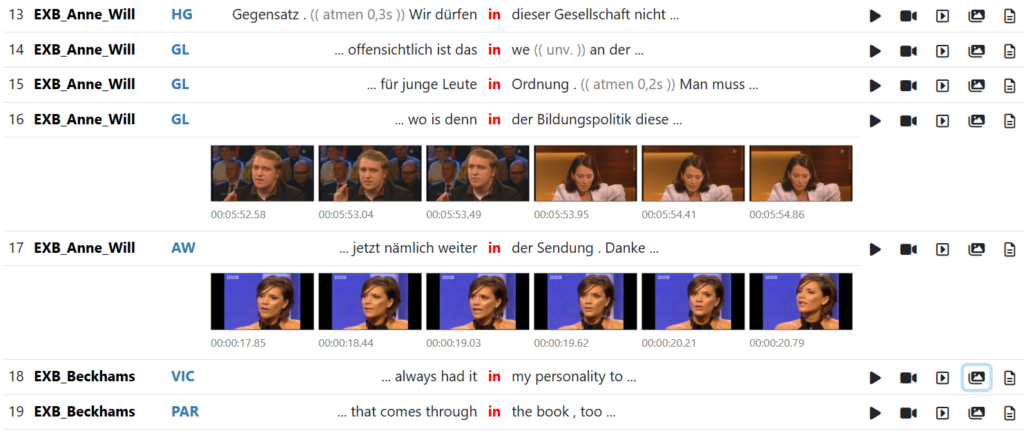
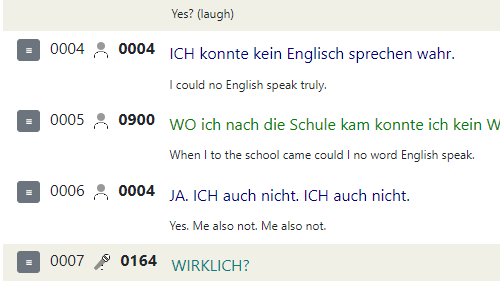
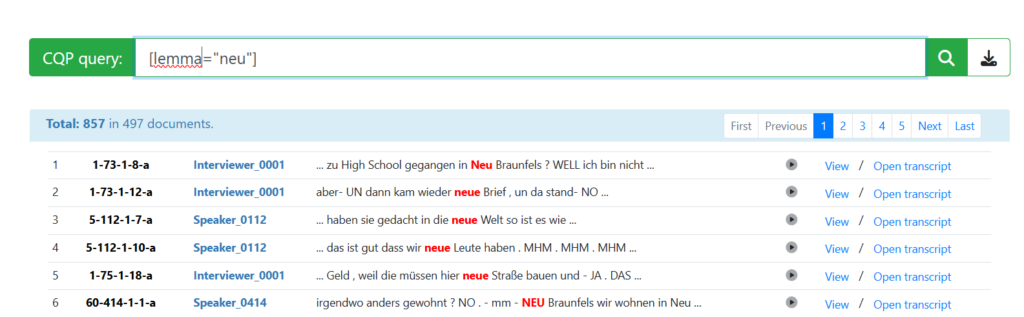
At the workshop „“Corpus linguistics 2040: Which data, which methods, which models?“ which took place at the Leibniz-Institute for the German Language on July 10th and 11th, Thomas Schmidt, Anne Ferger and Elena Frick presented a poster on:
Multimodal data and qualitative exploration of audiovisual language corpora – the ZuMult corpus platform in 2025
The poster is available on Zenodo.
As on many other occasions of a similar kind, we felt it was our duty to remind the audience of the relevance of oral data and audiovisual language data. We did so by pitching our poster with a little poem:
Corpus linguists, be awoken
To the importance of the spoken token
Billions of written words are well and good
But language can be fully understood
Only by looking at its use in interaction
with speakers’ and listeners’ reactions,
Including the empirical reality
Inherent in multimodality,
the use of words in conversation,
The dialectal variation,
Stages of language acquisition
Under different conditions,
and not to forget: phonology.
For this, we need technology.
We have therefore invented
A platform that will be presented
In a much more detailed fashion
As part of our poster session.
We keep trying 😉