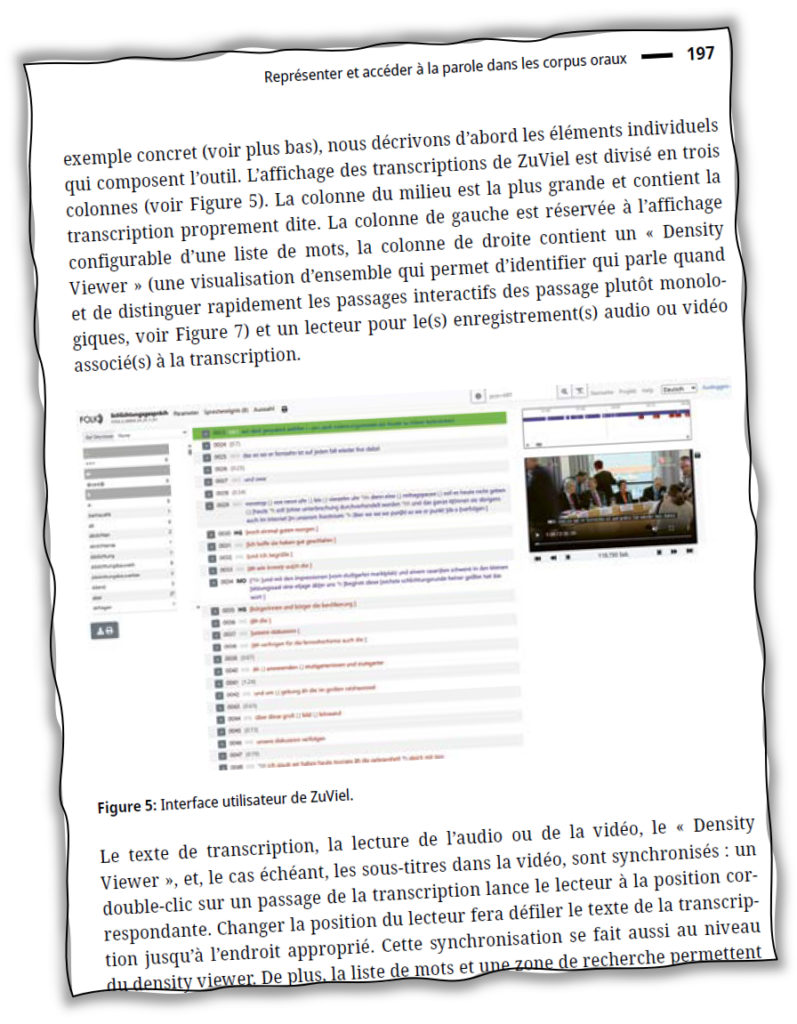
UT Austin and linguisticbits.de have released a new version of the ZuMult platform for the 𝗧𝗲𝘅𝗮𝘀 𝗚𝗲𝗿𝗺𝗮𝗻 𝗗𝗶𝗮𝗹𝗲𝗰𝘁 𝗽𝗿𝗼𝗷𝗲𝗰𝘁 (TGDP). Besides additional transcribed interviews from the TGDP, an additional annotation layer for Universal Dependency POS tags, and a couple of improvements to the frontend (streamlined navigation, improvements to the KWIC display and more), this new version also contains the „𝗵𝗶𝘀𝘁𝗼𝗿𝗶𝗰𝗮𝗹“ 𝗶𝗻𝘁𝗲𝗿𝘃𝗶𝗲𝘄𝘀 𝗰𝗼𝗻𝗱𝘂𝗰𝘁𝗲𝗱 𝗯𝘆 𝗚𝗹𝗲𝗻𝗻 𝗚𝗶𝗹𝗯𝗲𝗿𝘁 𝗶𝗻 𝘁𝗵𝗲 𝟭𝟵𝟲𝟬𝘀 with speakers of Texas German. This adds a diachronic dimension to the study of Texas German.
The new version is at https://tgdp-zumult.la.utexas.edu/index.jsp.